Preface
For Android applications, especially large applications, build time is a headache. Build times of several minutes or even tens of minutes are intolerable for most developers. What we face most in actual development is local incremental compilation. Although the official has done some processing on incremental compilation, the actual effect is not ideal, especially in specific projects, particularly medium and large projects.
Background
Currently NetEase Cloud Music and its subordinate look live broadcast, xinyu, mus and other app have successively adopted the aar of public modules, using the latest agp version and other measures, but the overall build time is still long, incremental build is generally 2-5 min. Since I am currently mainly responsible for the development of mus business, I have done some optimization work on incremental builds based on the current build situation of mus.
Time Consuming Investigation
Combining with the specific situation of mus construction, the main focus of the current build time consumption is concentrated in some Transform and dexMerge (agp version 4.2.1).
For Transform, the main consumption is from some tools like privacy scanning, automated buried points and so on, usually the build time of these Transform has reached several minutes incrementally.
In addition, the dexMeger task is also a big head during incremental builds. The incremental dexMerge build time for mus is about 35-40s, and the incremental build dexMerge time for NetEase Cloud Music is about 90-100s.
Optimization Direction
For large projects, basically the most time-consuming is Transform. These Transform generally fall into the following two categories:
- Functional
Transform, removing only affects its own functional part, does not affect the build artifacts and project operation. For example: buried point verification, privacy scanning. -
Strong dependent
Transform, removal affects compilation or normal operation of the project. This part usually collects some information inapt, and then generatesclassduringTransformexecution, and calls execution at runtime.
Functional Transform can be avoided during development by compilation switches and debug/release judgments. For strongly dependent Transform, the Transform process can be flattened through open source tools like byteX from ByteDance, which is effective for both incremental and full builds. However, byteX has greater intrusiveness and requires existing Transform to be subclasses of the Transform provided by ByteDance. Here we use a lightweight approach to modify the build input to optimize incremental builds for Transform.
At the same time, for the time-consuming points of dex related operations, incremental optimization can be combined with the actual process of dexMerge to ensure that only the minimum granularity of changes will trigger the merge operation of dex.
Incremental Build of Trasnform
Although the isIncremental configuration of most Transform dependent by mus currently returns true, there is little incremental logic in the actual io and instrumentation.
During incremental builds, most class have been processed by each Transform during the first build, instrumented and moved to the corresponding next level Transform directory. Incrementally, there is no need to re-instrument and copy between each Transform for these processed artifacts.
The writing method of most Transform is as follows:
input.jarInputs.each { JarInput jarInput ->
ile destFile = transformInvocation.getOutputProvider().getContentLocation(destName , jarInput.contentTypes, jarInput.scopes, Format.JAR)
FileUtils.copyFile(srcFile, destFile)
}
input.directoryInputs.each { DirectoryInput directoryInput ->
File destFile = transformInvocation.getOutputProvider().getContentLocation(directoryInput.name, directoryInput.contentTypes, directoryInput.scopes, Format.DIRECTORY)
...
FileUtils.copyDirectory(directoryInput.file, destFile)
}
What should be done incrementally here is to only instrument and copy operations on artifacts that have changed:
// Pseudo code is as follows:
// Incremental processing of jar
if(!isIncremental) return
if (Status.ADDED ==jarInput.status || Status.CHANGED==jarInput.status){
File destFile = transformInvocation.getOutputProvider().getContentLocation(destName , jarInput.contentTypes, jarInput.scopes, Format.JAR)
FileUtils.copyFile(srcFile, destFile)
}
// Incremental processing of class
val dest = outputProvider!!.getContentLocation(
directoryInput.name, directoryInput.contentTypes,
directoryInput.scopes, Format.DIRECTORY
)
if(Status.ADDED ==dirInput.status || Status.CHANGED==dirInput.status){
dirInput.changedFiles.forEach{
// Instrumentation logic
...
// Only move incrementally changed instrumented class files to corresponding directory
copyFileToTarger(it,dest)
}
}
Of course, due to some historical reasons, some Transform code may not be found at all, and cannot be refactored. Therefore, to be compatible with all situations, the input artifacts of Transform are simply replaced and hooked here.
Usually implementing a Transform is to create a class that implements the transform method of Trasnform, and execute specific operations in the transform method. The parameters of the Trasnform artifacts are in the method com.android.build.api.transform.TransformInvocation#getInputs:
public interface TransformInvocation {
Context getContext();
/**
* Returns the inputs/outputs of the transform.
* @return the inputs/outputs of the transform.
*/
@NonNull
Collection<TransformInput> getInputs();
...
}
By hooking TransformInvocation#getInputs to return JarInput and DirectoryInput, unchanged artifacts in JarInputs and Directory are removed.
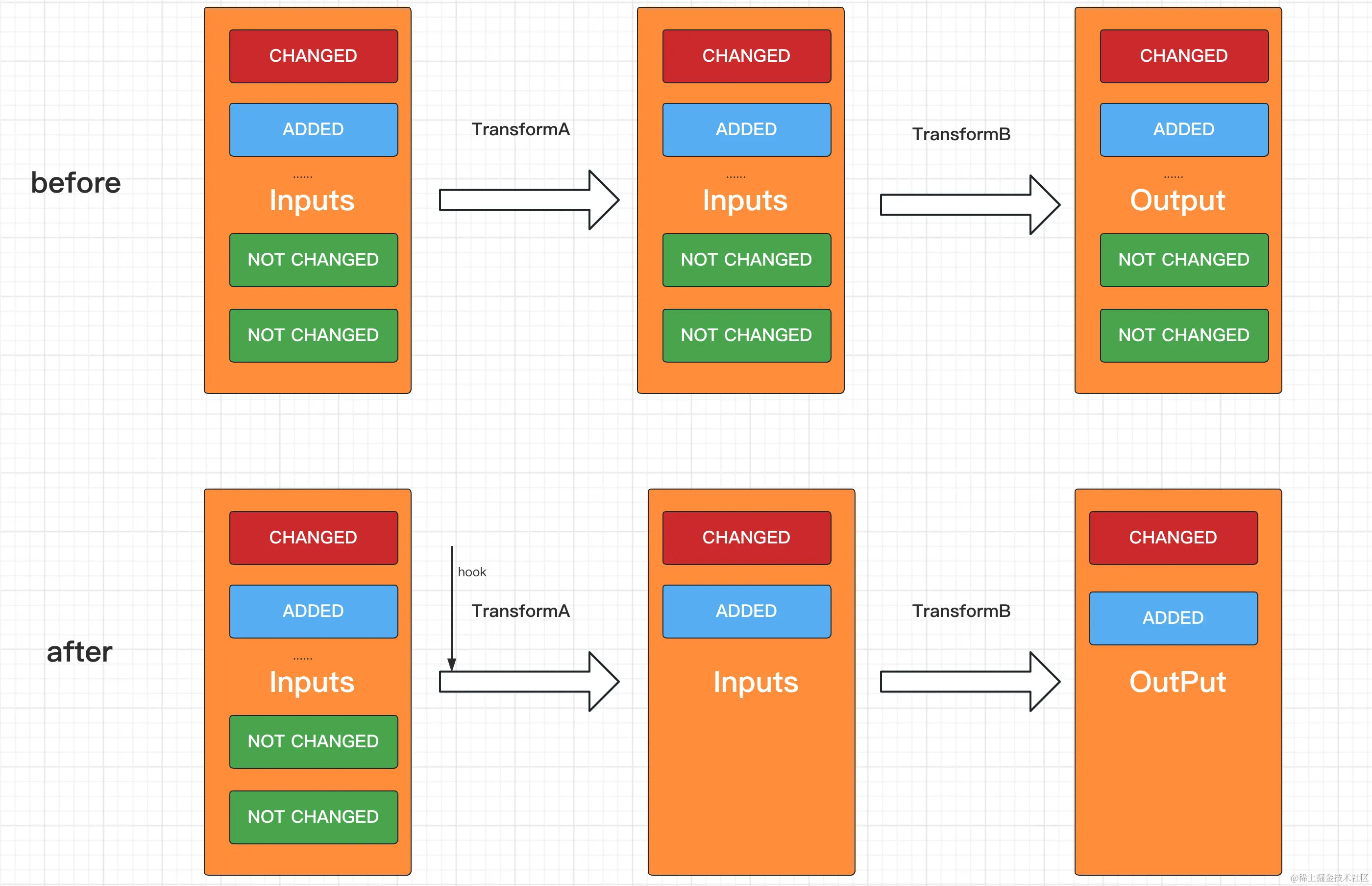
After the above optimization, Transform, which used to take tens of seconds to several minutes, can be compressed to within 1-2 s.
Incremental Optimization of DexMerge
In fact, the agp version is updated very frequently. For different versions, the dex consumption is different. For 3.x versions, the main dex related task consumption is concentrated on dexBuilder, while for 4.x versions, the main consumption is concentrated on dexMerger. Since mus and other businesses currently use 4.2 and above versions of agp, it was found that 4.x versions actually do incremental processing on dexBuilder, and the overall consumption is not much. Therefore, the main optimization is for the dexMerger consumption of 4.2 and above versions.
As the name implies, dexMerge actually merges the exported dex and combines multiple dex or jar into a larger dex process. Under normal circumstances, the more dex, the slower the application startup. Therefore, dexMerge is also an indispensable step for large projects.
dexMerge Process
dexMerger has bucketing operations, the number of buckets is usually the default value of 16, and the bucket allocation logic is usually based on the package name, that is, class with the same package name will be allocated to the same bucket.
fun getBucketNumber(relativePath: String, numberOfBuckets: Int): Int {
...
val packagePath = File(relativePath).parent
return if (packagePath.isNullOrEmpty()) {
0
} else {
when (numberOfBuckets) {
1 -> 0
else -> {
// Class with the same package name is divided into the same bucket
val normalizedPackagePath = File(packagePath).invariantSeparatorsPath
return abs(normalizedPackagePath.hashCode()) % (numberOfBuckets - 1) + 1
}
}
}
}
public val File.invariantSeparatorsPath: String
get() = if (File.separatorChar != '/') path.replace(File.separatorChar, '/') else path
The actual build artifacts are as follows:
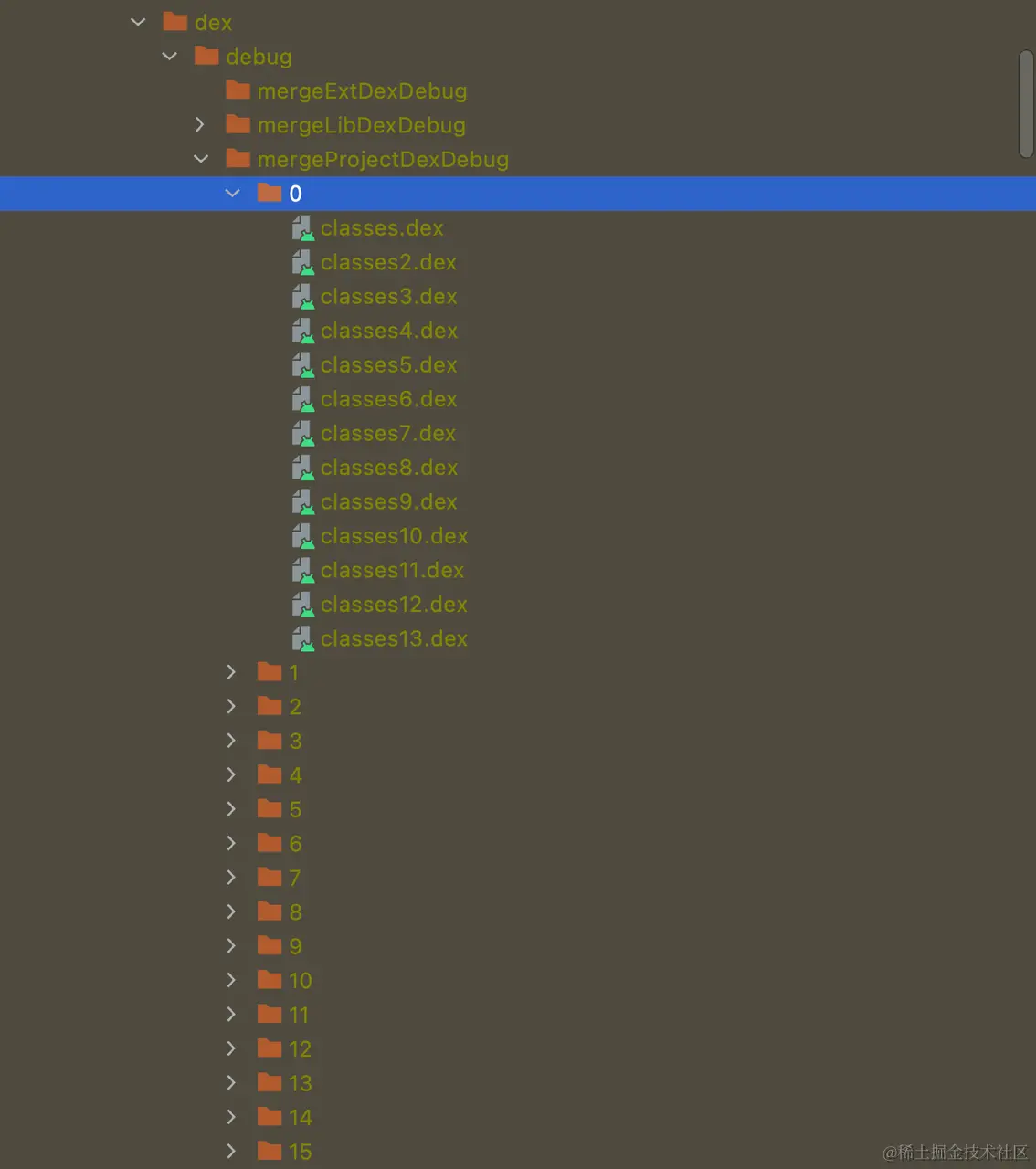
During incremental builds, agp executes the dexMerge task according to the following rules:
- If there is a change in the status of the
jarfile or it is removed, that is, the corresponding status isCHANGEDorREMOVE, in this case all buckets need to go through thedexMergeprocess again. Usually the default number ofbucketis 16, that is, when ajarfile changes during construction, all input artifacts will participate in thedexMegerprocess. (Although thed8command line tool itself has some incremental optimization fordexMeger, the incremental speed compared to the full amount will be accelerated to some extent, but overall it is still slow for large projects.)
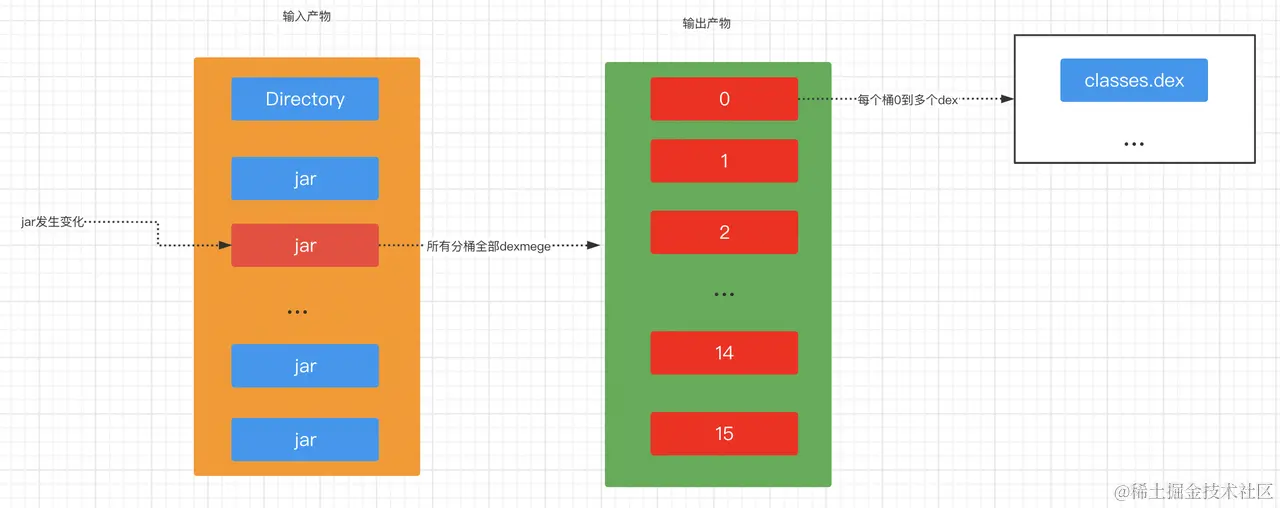
- If only new
jarordexchanges in theDirectorystatus, the corresponding bucket array will be obtained according to the package name, and only incremental packaging will be performed on the found bucket array. This is what we said about the incremental operation ofdexMergeitself.
The code to return the corresponding bucket id array is as follows:
private fun getImpactedBuckets(
fileChanges: SerializableFileChanges,
numberOfBuckets: Int
): Set<Int> {
val hasModifiedRemovedJars =
(fileChanges.modifiedFiles + fileChanges.removedFiles)
.find { isJarFile(it.file) } != null
if (hasModifiedRemovedJars) {
// 1. If there is CHANGED or REMOVE status jar, return all bucket arrays.
return (0 until numberOfBuckets).toSet()
}
// 2. If it is a new jar, or there are class changes in the directory, return the calculated bucket array.
val addedJars = (fileChanges.addedFiles).map { it.file }.filter { isJarFile(it) }
val relativePathsOfDexFilesInAddedJars =
addedJars.flatMap { getSortedRelativePathsInJar(it, isDexFile) }
val relativePathsOfChangedDexFilesInDirs =
fileChanges.fileChanges.map { it.normalizedPath }.filter { isDexFile(it) }
return (relativePathsOfDexFilesInAddedJars + relativePathsOfChangedDexFilesInDirs)
.map { getBucketNumber(it, numberOfBuckets) }.toSet()
}
This incremental operation applies to most businesses where the code is included in the shell project and the underlying libraries are not frequently changed. I don't know if it's because the development model of foreign projects including Google's own projects is like this. For most domestic projects, as long as you have modularization, or even no business modularization but multiple submodule types of projects, as long as there are changes involved in the submodules, all artifacts will have to participate in dexMerge.
For mus, NetEase Cloud Music and other componentized projects, usually only the shell project is in the form of a folder as an input artifact in subsequent Transform and dex related processes, while the submodule is usually in the form of jar Participate in the build, and what we usually develop is the change of each business module, corresponding to the first case above, all buckets will re-run dexMerger, and the second case will only change the shell project code or add dependencies. New modules and other situations rarely occur and can be ignored.
To ensure that the minimum unit of dex participates in the subsequent dexMerge process, we mainly use the second method as the incremental build scheme for dexMerge.
There are two main solutions to the above problem:
- Decompose all
jarinto folders, so that only the bucket split of the changed module takes effect, but the problem with this is that even if only two classes in a module are changed, since thebucketis fixed in the same bucket according to the package name, if not the same package name, the bucket is randomly divided, it is likely that otherbucketwill also bedexMergertogether, although appropriately increasing the number of splits can alleviate this problem to some extent. -
Only re-
dexMergerthe changed input artifacts, and add the newly generated mergeddexto theapkor move it to the device to ensure the incremental changed part of the code can be executed at runtime.
In order to minimize the unit of dex involved in the subsequent dexMerge process, we adopt the second method as the incremental build scheme for dexMerge.
Incremental Build Products DexMerge
By hooking the key processes of dexMerge, we can get the changed jar files and folders containing dex, then modify the input artifacts of dexMerge from all artifacts to the artifacts we hooked:
We collectively move all changed dex files to a temporary file directory, then use the target folder as an input artifact, for changed jars, we also add them to the input artifacts, then continue with the original dexMerge process.
The incremental dex build artifact is as follows:
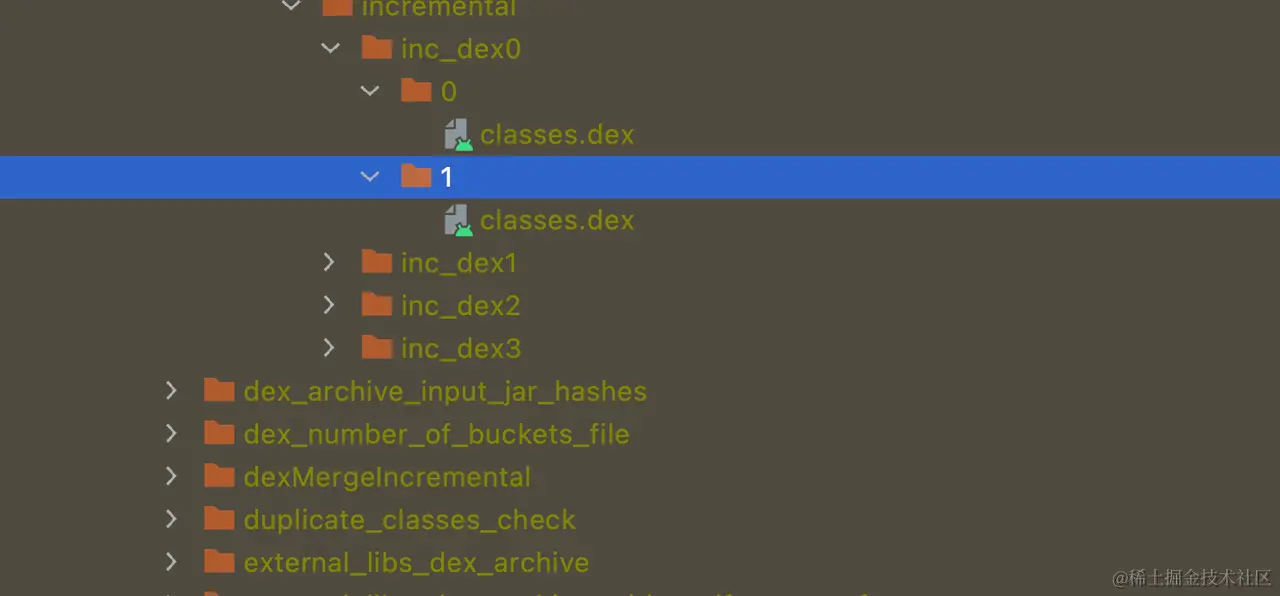
At the same time, we need to change the output directory of incremental dexMerge because during normal dexMerger running, when there is code modification, all buckets will be overwritten by new artifacts, even if the new artifacts are empty folders. If the file directory is not changed, all full dex output before will be overwritten, resulting in the final apk package containing only the incremental dex of this build, so it cannot run properly.
Also, since the build artifacts change each incremental build, the output directory of each build artifact is incremented to ensure the artifacts of the previous incremental build are not overwritten. The artifacts of each build are useful for subsequent build processes, which will be explained later.
Of course, where exactly the new directory is located also depends on the scheme we choose.
Hot Update Solution
With the incremental dex, we can easily think of a hot update solution, which is to push the incrementally built dex to the phone's sd card, then dynamically load it at runtime. In this case, where the incremental merge dex artifacts are located does not matter much, because it has little impact on subsequent build processes, mainly affecting the dex loading logic at runtime.
1. Incremental dex temporary artifacts
Although we have incremental build artifacts, in order to facilitate sorting at runtime, we still move the newly compiled dex of each build to the temporary pulledMergeDex folder.
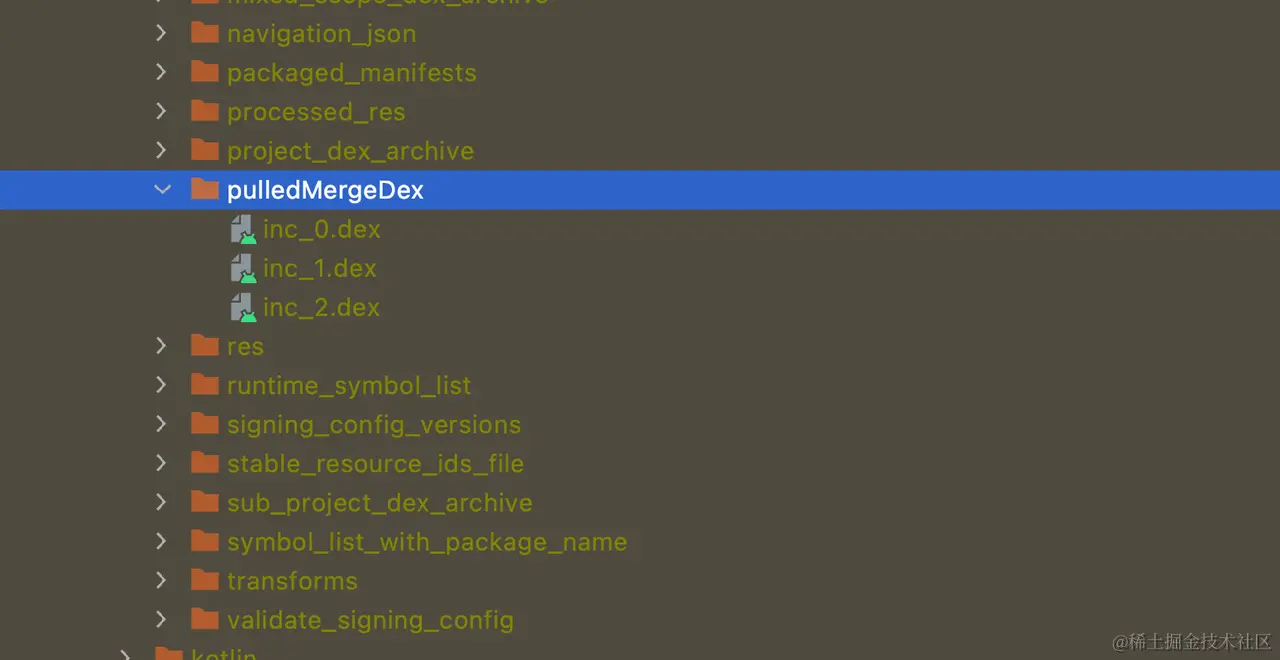
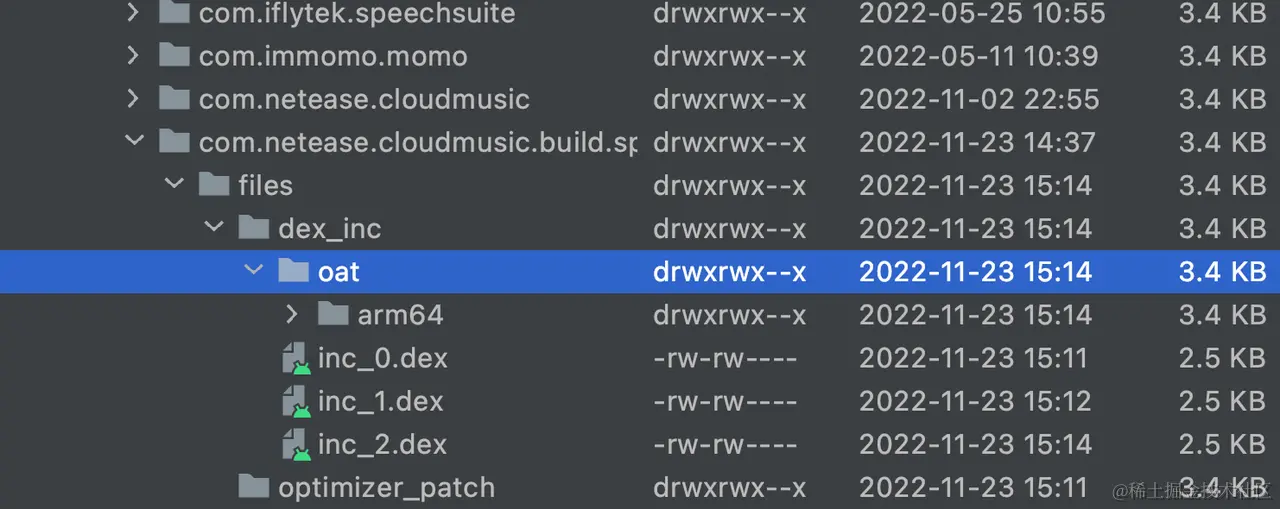
Then we batch clear the temporary dex on the device via adb, and push all dex under the pulledMergeDex directory to the device. This ensures the accuracy of dex on the device and avoids the impact of residual dex artifacts from previous builds on current code logic.
2. Dynamically load dex at runtime
Since dex is loaded in the order of the PathList loading the dexElements array from front to back, we just need to reflect and replace the dexElements array in PathClassLoader at runtime following the hot update solution of dex, sort the previously pushed array to the phone directory in reverse order, and insert it at the front of the dexElements array, the specific principles of hot updates are not explained here.
After integrating with the project, it was found that some code changes did not take effect (mainly Application and class directly referenced by Application).safemode=true was added to the local AndroidMainfest file, but it was still invalid on the actual device. I don't know if the current device version no longer supports it. Another feasible approach is to transform Application similar to tinker's solution, and then load subsequent class via another ClassLoader.
Dex Re-ordering Solution
In addition to loading dex at runtime, we can also try to package incremental dex into apk at compile time.
The corresponding tasks in gradle all have build caches. If we put the incremental dex in a random directory, when the input artifacts of subsequent tasks such as package and assemble do not change, it will directly use the incremental build cache without executing again. But we want our incremental dex to be packaged into the apk, so subsequent tasks like package must be executed.
In this case, the build artifact directory is quite important. We can take a shortcut by adding an incremental folder under the directory where the full dexMeger artifacts were output before. This is dedicated to incremental dexMeger artifacts. Similarly, each incremental artifact in this file directory is incremented by index to avoid conflicts.

The dex packaged into the apk is also loaded and executed in the order of the dex arrangement, so we need to arrange the new dex at the very front of the apk during compilation. The sorting of dex in the apk is performed in the package task, so we need to try to hook the key paths of package and arrange our new dex at the front of the dex array in the Apk.
Android Package Process Hook
Android package is responsible for packaging all artifacts from previous packaging processes into the final output apk product, including dex of course. Android package will update changed files in the apk by combining product changes, deleting files in apk compared to CHANGED and REMOVED, and then re-adding artifacts from the build artifacts that are ADDED and CHANGED to the apk.
public void updateFiles() throws IOException {
// Calculate packagedFileUpdates
List<PackagedFileUpdate> packagedFileUpdates = new ArrayList<>();
// Changes to dex files
packagedFileUpdates.addAll(mDexRenamer.update(mChangedDexFiles));
...
deleteFiles(packagedFileUpdates);
...
addFiles(packagedFileUpdates);
}
private void deleteFiles(@NonNull Collection<PackagedFileUpdate> updates) throws IOException {
// Remove current CHANGED REMOVED status files from apk
Predicate<PackagedFileUpdate> deletePredicate =
mApkCreatorType == ApkCreatorType.APK_FLINGER
? (p) -> p.getStatus() == REMOVED || p.getStatus() == CHANGED
: (p) -> p.getStatus() == REMOVED;
...
for (String deletedPath : deletedPaths) {
getApkCreator().deleteFile(deletedPath);
}
}
private void addFiles(@NonNull Collection<PackagedFileUpdate> updates) throws IOException {
// NEW CHANGED status files added to apk
Predicate<PackagedFileUpdate> isNewOrChanged =
pfu -> pfu.getStatus() == FileStatus.NEW || pfu.getStatus() == CHANGED;
...
for (File arch : archives) {
getApkCreator().writeZip(arch, pathNameMap::get, name -> !names.contains(name));
}
}
The file relationship is maintained via DexIncrementalRenameManager. DexIncrementalRenameManager loads the current dex mapping from dex-renamer-state.txt each time, and updates files in the apk by combining changed dex. It also updates the new dex mapping to dex-renamer-state.txt after each sort.
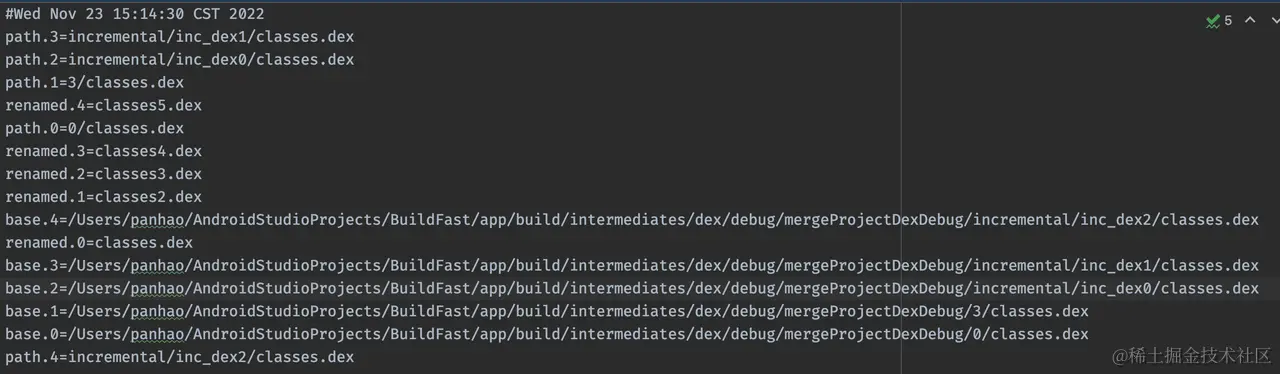
We refer to the original mapping file here. During each compilation, associate the dex path in the build artifacts with the actual dex path classesX.dex in the apk for each dex, and keep them in a separate dex_mapping file.

When there are new merged dex for each incremental compilation, first arrange the incremental dex in the order of classes.dex, classes2.dex, etc., then load the relationship between build artifacts and apk dex paths in dex-mapping into memory, arrange them in the original order after the incremental dex, and finally synchronize and update the changes to the apk file by hooking the package process.
The overall process is as follows:
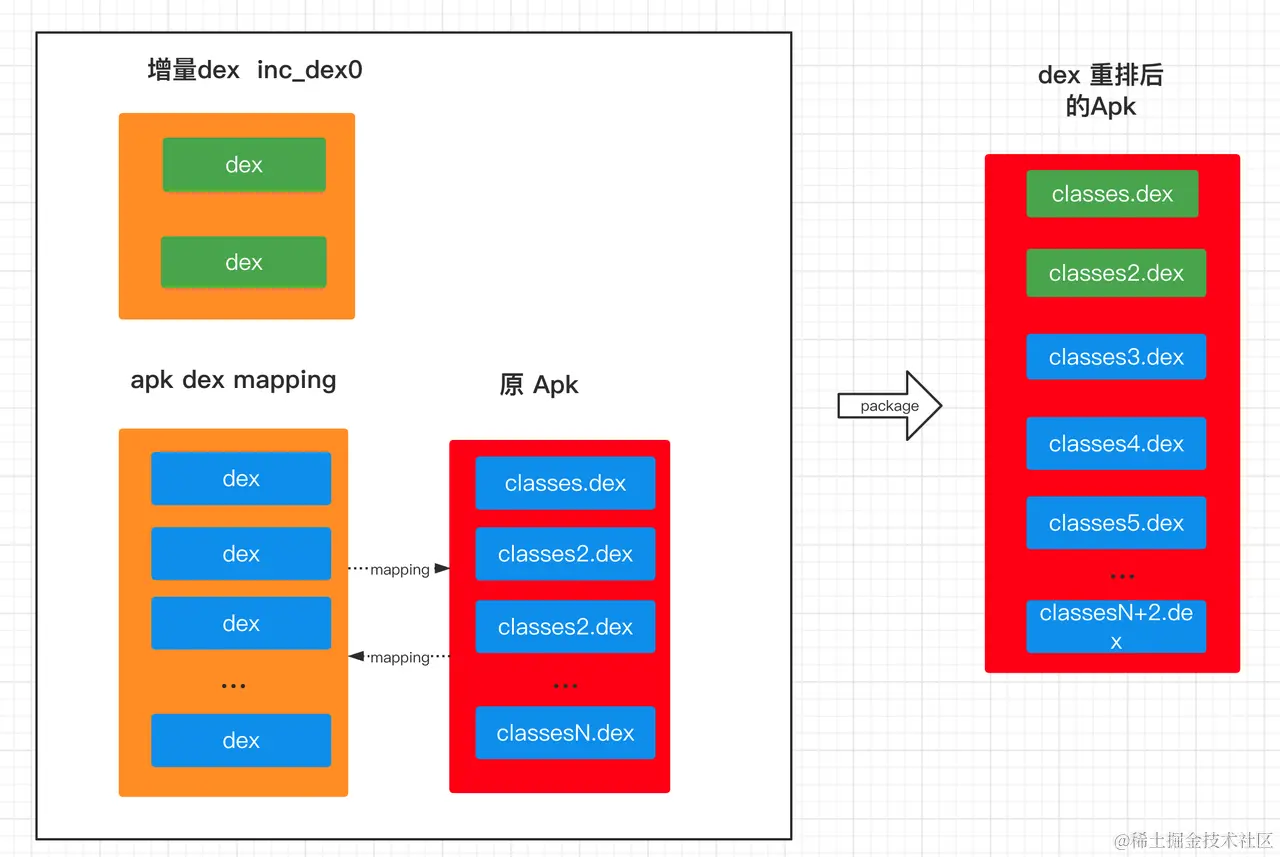
After the apk update is complete, rewrite the latest dex and apk dex path mapping relationship back to the dex_mapping file to record the latest dex and apk path relationship. To avoid having all dex participate in re-ordering every time, you can reserve a certain number of slots in classes.dex and classesN.dex to avoid re-ordering all dex each time.
In testing, package will have a slight increase in elapsed time, generally within 1s. The overall dexMerge elapsed time of mus is reduced from 35-40 s to about 3 s.
Currently both solutions of this incremental build component are supported. Just be aware that the hot update solution may involve transforming Application.
Optimization Effect
With the above optimization schemes, under ideal conditions, changing a line in the simplest kotlin class in a submodule in mus takes about 10s for total task elapsed time (excluding configure). Looking at actual development, it is generally between 20-40s. This elapsed time is mainly because the changed class and modules are often more than one in actual development, and also includes the elapsed time of configure, which currently cannot be avoided. It also includes the elapsed time of class compilation, kapt, incremental judgment, etc., and will also be affected by device cpu, real-time memory, etc.
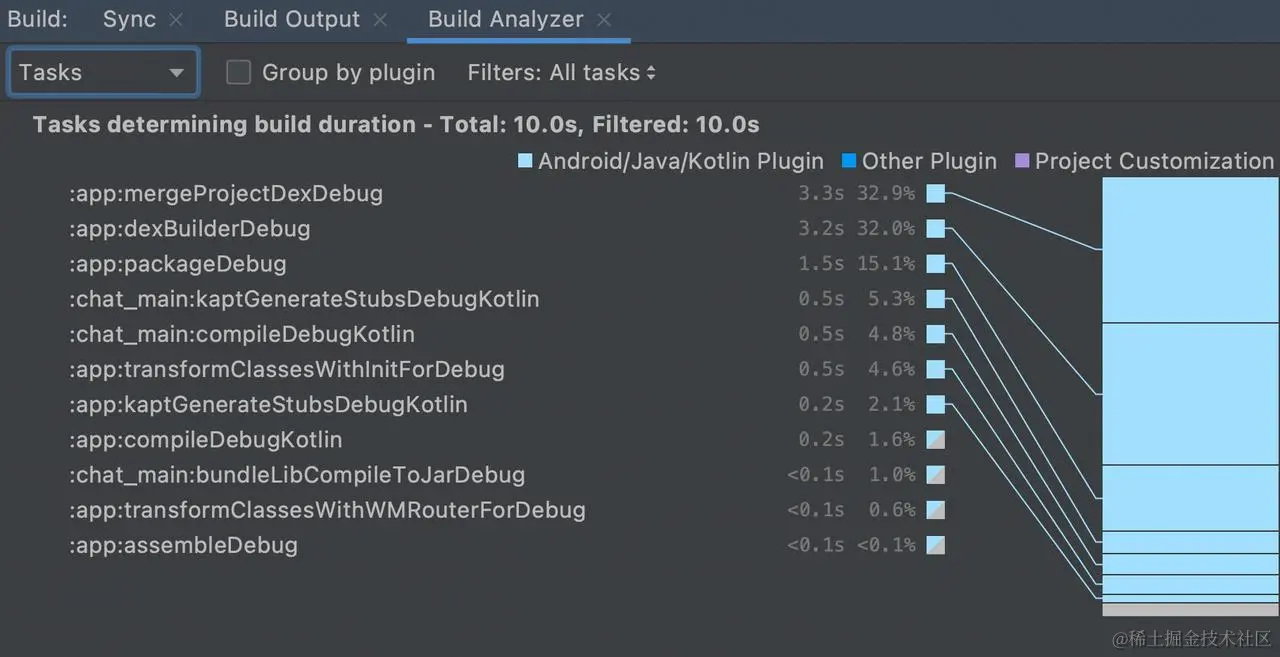
The above data is based on my computer, 2.3 GHz Quad-Core Intel Core i7, 32 GB 3733 MHz LPDDR4X. Data run on different devices will vary slightly, but the overall optimization effect is still very obvious.
Summary
With the optimization solutions above, the overall incremental build speed is at a relatively low level. Of course there are still further optimization spaces such as kotlin compilation, kapt, incremental judgment, etc. I look forward to sharing more when further optimization of tasks is complete.

Comments